jueves, 28 de mayo de 2015
martes, 19 de mayo de 2015
Actividad #20
ENLACE PARA LA PRESENTACION
https://drive.google.com/open?id=0BwdKiO11D1ZDV0k4RGVGSHB3eGs&authuser=0
https://drive.google.com/open?id=0BwdKiO11D1ZDV0k4RGVGSHB3eGs&authuser=0
Actividad #21
Protocolos REDO/UNDO
El
registro de la base de datos contiene información que es utilizada por
el proceso de recuperación para restablecer la base de datos a un estado
consistente. Esta información puede incluir entre otras cosas:
- el identificador de la transacción,
- el tipo de operación realizada,
- los datos accesados por la transacción para realizar la acción,
- el valor anterior del dato (imagen anterior), y
- el valor nuevo del dato (imagen nueva).
El DBMS inicia la ejecución en el tiempo 0 y en el tiempo t se presenta una falla del sistema. Durante el periodo [0, t] ocurren dos transacciones, T1 y T2. T1 ha sido concluida (ha realizado su commit) pero T2 no pudo ser concluida.
La propiedad de durabilidad requiere que los efectos de T1 sean
reflejados en la base de datos estable. De forma similar, la propiedad
de atomicidad requiere que la base de datos estable no contenga alguno
de los efectos de T2.
Protocolo 2PC de confiabilidad distribuida.
El
protocolo 2PC básico un agente (un agente-DTM en el modelo) con un rol
especial. Este es llamado el coordinador; todos los demás agentes que
deben hacer commit a la vez son llamados participantes.
El
coordinador es responsable de tomar la decisión de llevar a cabo un
commit o abort finalmente. Cada participante corresponde a una
subtransacción la cual ha realizado alguna acción de escritura en su
base de datos local.
Se
puede asumir que cada participante está en un sitio diferente. Aun si
un participante y el coordinador se encuentran en el mismo sitio, se
sigue el protocolo como si estuvieran en distintos sitios.
La
idea básica del 2PC es determinar una decisión única para todos los
participantes con respecto a hacer commit o abort en todas las
subtransacciones locales.
El protocolo consiste en dos fases:
- La primera fase tiene como objetivo alcanzar una decisión común,
- La meta de la segunda fase es implementar esta decisión.
El protocolo procede como sigue:
Fase uno:
• El
coordinador escribe “prepare” en la bitácora y envía un mensaje donde
pregunta a todos los participantes si preparan el commit (PREPARE).
• Cada
participante escribe “ready” (y registra las subtransacciones) en su
propia bitácora si está listo o “abort” de lo contrario.
• Cada participante responde con un mensaje READY o ABORT al coordinador.
• El
coordinador decide el commit o abort en la transacción como un
resultado de las respuestas que ha recibido de los participantes. Si
todos respondieron READY, decide hacer un commit. Si alguno ha
respondido ABORT o no ha respondido en un intervalo de tiempo
determinado se aborta la transacción.
Fase dos:
• El
coordinador registra la decisión tomada en almacenamiento estable; es
decir, escribe “global_commit” o “global_abort” en la bitácora.
• El coordinador envía mensaje de COMMIT o ABORT según sea el caso para su ejecución.
• Todos
los participantes escriben un commit o abort en la bitácora basados en
el mensaje recibido del coordinador (desde este momento el procedimiento
de recuperación es capaz de asegurar que el efecto de la subtransacción
no será perdido).
Finalmente:
- Todos los participantes envían un mensaje de acuse de recibo (ACK) al coordinador, y ejecutan las acciones requeridas para terminar (commit) o abortar (abort) la subtransacción.
- Cuando el coordinador ha recibido un mensaje ACK de todos los participantes, escribe un nuevo tipo de registro en la bitácora, llamado un registro “completo”.
Puntos de verificación (checkpoints).
Cuando
ocurre una falla en el sistema es necesario consultar la bitácora para
determinar cuáles son las transacciones que necesitan volver a hacerse y
cuando no necesitan hacerse. Estos puntos de verificación nos ayudan
para reducir el gasto de tiempo consultando la bitácora. El punto de
verificación es un registro que se genera en la bitácora para concluir
en todo lo que se encuentra antes de ese punto está correcto y
verificado.
Actividad #19
Disciplinas del Interbloqueo: prevención, detección, eliminación y recuperación.
Un interbloqueo se produce cuando dos o más tareas se bloquean entre sí permanentemente teniendo cada tarea un bloqueo en un recurso que las otras tareas intentan bloquear.
Un interbloqueo es una condición que se puede dar en cualquier sistema con varios subprocesos, no
sólo en un sistema de administración de bases de datos relacionales, y
puede producirse para recursos distintos a los bloqueos en objetos de
base de datos
Por ejemplo:
- La transacción A tiene un bloqueo compartido de la fila 1.
- La transacción B tiene un bloqueo compartido de la fila 2.
- La transacción A ahora solicita un bloqueo exclusivo de la fila 2 y se bloquea hasta que la transacción B finalice y libere el bloqueo compartido que tiene de la fila 2.
- La transacción B ahora solicita un bloqueo exclusivo de la fila 1 y se bloquea hasta que la transacción A finalice y libere el bloqueo compartido que tiene de la fila 1.
Prevención del interbloqueo.
Objetivo: conseguir que sea imposible la aparición de situaciones de interbloqueo.
Impedir
que se produzca una de las cuatro condiciones necesarias para
producirlo: Exclusión mutua, Retención y espera, No expropiación, y
Espera circular.
Condicionar un sistema para quitar cualquier posibilidad de ocurrencia de interbloqueo.
Que no se cumpla una condición necesaria
- “Exclusión mutua” y “sin expropiación” no se pueden relajar. Dependen de carácter intrínseco del recurso.
- Las otras dos condiciones son más prometedoras.
Recuperación de Interbloqueo.
Limpiar un sistema de interbloqueos, una vez que fueron detectados.
Cuando
se ha detectado que existe un interbloqueo, podemos actuar de varias
formas. Una posibilidad es informar al operador que ha ocurrido un
interbloqueo y dejar que el operador se ocupe de él manualmente. La otra
posibilidad es dejar que el sistema se recupere automáticamente del
interbloqueo. Dentro de esta recuperación automática tenemos dos
opciones para romper el interbloqueo: Una consiste en abortar uno o más
procesos hasta romper la espera circular, y la segunda es apropiar
algunos recursos de uno o más de los procesos bloqueados.
Eliminar interbloqueos.
Para
eliminar interbloqueos abortando un proceso, tenemos dos métodos; en
ambos, el sistema recupera todos los recursos asignados a los procesos
terminados.
- Abortar todos los procesos interbloqueados. Esta es una de las soluciones más comunes, adoptada por Sistemas Operativos. Este método romperá definitivamente el ciclo de interbloqueo pero con un costo muy elevado, ya que estos procesos efectuaron cálculos durante mucho tiempo y habrá que descartar los resultados de estos cálculos parciales, para quizá tener que volver a calcularlos más tarde.
- Abortar un proceso en cada ocasión hasta eliminar el ciclo de interbloqueo. El orden en que se seleccionan los procesos para abortarlos debe basarse en algún criterio de costo mínimo. Después de cada aborto, debe solicitarse de nuevo el algoritmo de detección, para ver si todavía existe el interbloqueo. Este método cae en mucho tiempo de procesamiento adicional.
Si
éste se encuentra actualizando un archivo, cortarlo a la mitad de la
operación puede ocasionar que el archivo quede en un mal estado.
Si
se utiliza el método de terminación parcial, entonces, dado un conjunto
de procesos bloqueados, debemos determinar cuál proceso o procesos debe
terminarse para intentar romper el interbloqueo. Se trata sobre todo de
una cuestión económica, debemos abortar los procesos que nos
representen el menor costo posible.
Actividad #18
Algoritmos de control de concurrencia
El
criterio de clasificación más común de los algoritmos de control deconcurrencia
es el tipo de primitiva de sincronización. Esto resulta en dos clases:
- Aquellos
algoritmos que están basados en acceso mutuamente exclusivo adatos compartidos
(candados o bloqueos).
- Aquellos que intentar ordenar la ejecución de las
transacciones de acuerdo a un conjunto de reglas (protocolos).
Basados en Bloqueos
En los algoritmos basados en candados, las
transacciones indican sus intenciones solicitando candados al despachador
(llamado el administrador de candados). Los candados son
de lectura (rl), también llamados compartidos, o de escritura (wl),
también llamados exclusivos. Como se aprecia en la tabla siguiente, los
candados de lectura presentan conflictos con los candados de escritura, dado
que las operaciones de lectura y escritura son incompatibles.
|
|
rl
|
wl
|
|
rl
|
Si
|
No
|
|
Wl
|
No
|
No
|
En sistemas basados en candados, el despachador es un administrador
de candados (LM). El administrador de transacciones le pasa al
administrador de candados la operación sobre la base de datos (lectura o
escritura) e información asociada, como por ejemplo el elemento de datos
que es accesado y el identificador de la transacción que está enviando la
operación a la base de datos. El administrador de candados verifica si el
elemento de datos que se quiere accesar ya ha sido bloqueado por un candado. Si
candado solicitado es incompatible con el candado con que el dato está
bloqueado, entonces, la transacción solicitante es retrasada. De otra forma, el
candado se define sobre el dato en el modo deseado y la operación a la base de
datos es transferida al procesador de datos. El administrador de transacciones
es informado luego sobre el resultado de la operación. La terminación de una
transacción libera todos los candados y se puede iniciar otra transacción
que estaba esperando el acceso al mismo dato.
Basados en estampas de tiempo
Los
algoritmos basados en estampas de tiempo no pretenden mantener la seriabilidad
por exclusión mutua. En lugar de eso, ellos seleccionan un ordende
serialización a prioridad y ejecutan las transacciones, de acuerdo a ellas. Para
establecer este ordenamiento, el administrador de transacciones le asigna a cada
transacción T1 una estampa de tiempo única t1 (T1) cuando ésta inicia.Una
estampa de tiempo es un identificador simple que sirve para identificar cada
transacción de manera única.
A
diferencia de los algoritmos basados en candados, los algoritmos basados en
marcas de tiempono pretenden mantener la seriabilidad por la exclusión mutua.
En su lugar eligen un orden deserializacion en primera instancia y ejecutan las transacciones de acuerdo a ese orden. Enestos
algoritmos cada transacción lleva asociada una marca de tiempo. Cada dato lleva
asociadodos marcas de tiempo: uno de lectura y otro de escritura, que reflejan
la marca de tiempo de latransacción que hizo la ultima operación de ese tipo sobre el dato. Para leer la
marca de tiempo de escritura del dato, debe ser menor que el de la transacción,
si no aborta.Para escribir las marcas de tiempo de escritura y lectura del
dato, deben ser menores que el de latransacción, sino se aborta. Estatécnica
esta libre de Ínterbloqueos pero puede darse que halla que repetir varias veces
latransacción. En los sistemas distribuidos se puede usar un mecanismo como,
los relojes deLamport para asignar marcas de tiempo.El conjunto de algoritmos
pesimistas esta formado por algoritmos basados en candados,algoritmos basados
en ordenamiento por estampas de tiempo y algoritmos híbridos. Los
algoritmosoptimistas se componen por los algoritmos basados en candados y
algoritmos basados enestampas de tiempo.
ALGORITMOS DE CERRADURA O BASADOS EN CANDADOS
En
los algoritmos basados en candados, las transacciones indican sus
intenciones solicitando candados al despachador (llamado el
administrador de candados) Los candados son de lectura , también
llamados compartidos, o de escritura , también llamados exclusivos.
En
sistemas basados en candados, el despachador es un administrador de
candados . El administrador de transacciones le pasa al administrador de
candados la operación sobre la base de datos (lectura o escritura) e
información asociada, como por ejemplo el elemento de datos que es
accesado y el identificador de la transacción que está enviando la
operación a la base de datos. El administrador de candados verifica si
el elemento de datos que se quiere accesar ya ha sido bloqueado por un
candado. Si el candado solicitado es incompatible con el candado con que
el dato está bloqueado, entonces, la transacción solicitante es
retrasada. De otra forma, el candado se define sobre el dato en el modo
deseado y la operación a la base de datos es transferida al procesador
de datos. El administrador de transacciones es informado luego sobre el
resultado de la operación. La terminación de una transacción libera
todos los candados y se puede iniciar otra transacción que estaba
esperando el acceso al mismo dato.Se
usan cerraduras o candados de lectura o escritura sobre los datos. Para
asegurar la secuencialidad se usa un protocolo de dos fases, en la fase
de crecimiento de la transacción se establecen los cerrojos y en la fase dedecrecimiento se
liberan los cerrojos. Hay que tener en cuenta que se pueden producir
ínterbloqueos. En los sistemas distribuidos el nodo que mantiene un dato
se encarga normalmente de gestionar los cerrojos sobre el mismo.
Candados de dos fases : En
los candados de dos fases una transacción le pone un candado a un
objeto antes de usarlo. Cuando un objeto es bloqueado con un candado por
otra transacción, la transacción solicitante debe esperar. Cuando una
transacción libera un candado, ya no puede solicitar más candados. En la
primera fase solicita y adquiere todos los candados sobre los elementos
que va a utilizar y en la segunda fase libera los candados obtenidos
uno por uno.Puede
suceder que si una transacción aborta después de liberar un candado,
otras transacciones que hayan accesado el mismo elemento de datos
aborten también provocando lo que se conoce como abortos en cascada. Para evitar lo anterior, los despachadores para candados de dos fases implementan lo que se conoce como loscandados estrictos de dos fases en los cuales se liberan todos los candados juntos cuando la transacción termina (con compromiso o aborta).
Candados de dos fases centralizados: En
sistemas distribuidos puede que la administración de los candados se
dedique a un solo nodo del sistema, por lo tanto, se tiene un
despachador central el cual recibe todas las solicitudes de candados del
sistema. La comunicación se presenta entre el administrador de
transacciones del nodo en donde se origina la transacción , el
administrador de candados en el nodo central y los procesadores de
datos de todos los nodos participantes. Los nodos participantes son
todos aquellos en donde la operación se va a llevar a cabo.
martes, 12 de mayo de 2015
Actividad #17
Control de Transacciones
Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que luego de una ejecución en la que se produce una falla es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
Estructura de las transacciones
Las transacciones planas consisten de una secuencia de operaciones primitivas encerradas entre las palabras clave begin y end. Por ejemplo,
Begin_transaction Reservación
. .
end.
En las transacciones anidadas las operaciones de una transacción pueden ser así mismo transacciones. Por ejemplo,
Begin_transaction Reservación
. . .
Begin_transaction Vuelo
. . .
end. {Vuelo}
. . .
Begin_transaction Hotel
. . .
end.
. . .
end.
Una transacción anidada dentro de otra transacción conserva las mismas propiedades que la de sus padres, esto implica, que puede contener así mismo transacciones dentro de ella. Existen restricciones obvias en una transacción anidada: debe empezar después que su padre y debe terminar antes que él. Más aún, el commit de una subtransacción es condicional al commit de su padre, en otras palabras, si el padre de una o varias transacciones aborta, las subtransacciones hijas también serán abortadas.
Las transacciones anidadas proporcionan un nivel más alto de concurrencia entre transacciones. Ya que una transacción consiste de varios transacciones, es posible tener más concurrencia dentro de una sola transacción. Así también, es posible recuperarse de fallas de manera independiente de cada subtransacción. Esto limita el daño a un parte más pequeña de la transacción, haciendo que costo de la recuperación sea menor.
Transacciones Centralizada y Distribuidas
El monitor de ejecución distribuida consiste de dos módulos: El administrador de transacciones (TM) y el despachador (SC). Como se puede apreciar en la Figura 5.2, el administrador de transacciones es responsable de coordinar la ejecución en la base de datos de las operaciones que realiza una aplicación. El despachador, por otra parte, es responsable de implementar un algoritmo específico de control de concurrencia para sincronizar los accesos a la base de datos.
Un tercer componente que participa en el manejo de transacciones distribuidas es el administrador de recuperación local cuya función es implementar procedimientos locales que le permitan a una base de datos local recuperarse a un estado consistente después de una falla.

Figura 5.2. Un modelo del administrador de transacciones.
Los administradores de transacciones implementan una interfaz para los programas de aplicación que consiste de los comandos:
Begin_transaction.
Read.
Write.
Commit.
Abort.
En la Figura 5.3 se presenta la arquitectura requerida para la ejecución centralizada de transacciones. Las modificaciones requeridas en la arquitectura para una ejecución distribuida se pueden apreciar en las Figura 5.4. En esta última figura se presentan también los protocolos de comunicación necesarios para el manejo de transacciones distribuidas.

Figura 5.3. Ejecución centralizada de transacciones.
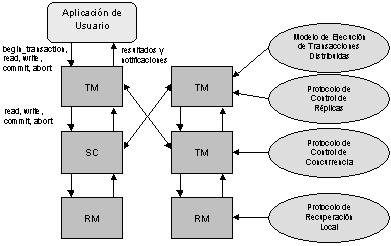
Figura 5.4. Ejecución distribuida de transacciones.
Exposicion:
miércoles, 6 de mayo de 2015
Actividad #16
Estrategias de procesamiento de consultas distribuidas
Las consultas distribuidas detienen acceso a datos de varios orígenes de datos heterogéneos. Estos orígenes de datos pueden estar almacenados en el mismo equipo o en equipos diferentes.
Contamos con la estrategia de Reformulacion de consultas, que nos sirve para encontrar que la información que nos va a proveer sea solo la que se le pidió por la fuente
También se cuenta con la estrategia de descomposición de las fuentes, que consiste en que según las fuentes que pidan cierto tipo de datos sean las atenidas con mayor velocidad.
Arboles de consultas
Pasos
– Parsing y traducción de la consulta
– Optimización
– Generación de código
– Ejecución de la consulta
Transformaciones equivalentes
Cuando una base de datos se encuentra en múltiples servidores ydistribuye a un número determinado de nodos tenemos:
•El servidor recibe una petición de un nodo.
•El servidor es atacado por el acceso concurrente a la base de datos cargada localmente.
•El servidor muestra un resultado y le da un hilo a cada una de las maquinas nodo de la red local.
Cuando una base de datos es acezada de esta manera la técnica que se utiliza es la de fragmentación de datos que puede ser hibrida, horizontal y vertical.
En esta fragmentación lo que no se quiere es perder la consistencia delos datos, por lo tanto se respetan las formas normales de la base de datos.
Bueno para realizar una transformación en la consulta primero desfragmentamos siguiendo los estándares marcados por las reglas formales y posteriormente realizamos el envió y la maquina que recibe es la que muestra el resultado pertinente para el usuario, de esta se puede producir una copia que será la equivalente a la original.
Metodos de ejecución del join
Existen diferentes algoritmos que pueden obtener transformacioneseficientes en el procesamiento de consultas.
Join en bucles (ciclos) anidados
Si z = r s, r recibirá el nombre de relación externa y s se llamará relación interna, el algoritmo de bucles anidados se puede presentar como sigue:
Para cada tupla tr en s si (tr,ts) si satisface la condición, entonces añadir tr * ts al resultado Donde tr * ts será la concatenación de las tuplas tr y ts. Como para cada registro de r se tiene que realizar una exploración completa de ts, y suponiendo el peor caso, en el cual la memoria intermedia sólo puede concatenar un bloque de cada relación, entonces el número de bloques a acceder es de sr bn b. Por otro lado, en el mejor de los casos si se pueden contener ambas relaciones en la memoria intermedia entonces sólo se necesitarían accesos a bloques.
Join en bucles anidados por bloques
Una variante del algoritmo anterior puede lograr un ahorro en el acceso a bloques, si se procesan las relaciones por bloques en vez de por tuplas. Para cada bloque Br dar a igual para cada bloque Bs de s, para cada tupla tr en Br.
La diferencia principal en costos de este algoritmo con el anterior es que en el peor de los casos cada bloque de la relación interna s se lee una vez por cada bloque de dr y no por cada tupla de la relación externa.
Join por mezcla
Este algoritmo se puede utilizar para calcular si un Join natural es óptimo en la búsqueda o consulta. Para tales efectos, ambas relaciones deben estar ordenadas para los atributos en común es decir se asocia un puntero a cada relación, al principio estos punteros apuntan al inicio de cada una de las relaciones. Según avance el algoritmo el puntero se mueve a través de la relación. De este modo se leen en memoria un grupo de tuplas de una relación con el mismo valor en los atributos de las relaciones.
¿Qué se debe de tomar en cuenta en este algoritmo?
•Se tiene que ordenar primero, para después utilizar este método.
•Se tiene que considerar el costo de ordenarlo / las relaciones.
•Es más fácil utilizar pequeñas tuplas.
Join por asociación.
Al igual que el algoritmo de join por mezcla, el algoritmo de join por asociación se puede utilizar para un Join natural o un equi-join. Este algoritmo utiliza una función de asociación h para dividir las tuplas de ambas relaciones. La idea fundamental es dividir las tuplas de cada relación en conjuntos con el mismo valor de la función de asociación en los atributos de join.
El número de bloques ocupados por las particiones podría ser ligeramente mayor que.
Debido a que los bloques no están completamente llenos. El acceso a estos bloques puede añadir un gasto adicional de 2·max a lo sumo, ya que cada una de las particiones podría tener un bloque parcialmente ocupado que se tiene que leer y escribir de nuevo.
Join por asociación híbrida
El algoritmo de join por asociación híbrida realiza otra optimización; es útil cuando el tamaño de la memoria es relativamente grande paro aún así, no cabe toda la relación s en memoria. Dado que el algoritmo de join por asociación necesita max +1 bloques de memoria para dividir ambas relaciones se puede utilizar el resto de la memoria (M – max – 1 bloques)para guardar en la memoria intermedia la primera partición de la relación s, esto es, así no es necesaria leerla ni escribirla nuevamente y se puede construir un índice asociativo.
Cuando r se divide, las tuplas de tampoco se escriben en disco; en su lugar, según se van generando, el sistema las utiliza para examinar el índice asociativo en y así generar las tuplas de salida del join. Después de utilizarlas, estas tuplas se descartan, así que la partición no ocupa espacio en memoria. De este modo se ahorra un acceso de lectura y uno de escritura para cada bloque de y.
Join Complejos
Los join en bucle anidado y en bucle anidado por bloques son útiles siempre, sin embargo, las otras técnicas de join son más eficientes que estas, pero sólo se pueden utilizar en condiciones particulares tales como join natural o equi-join. Se pueden implementar join con condiciones más complejas tales como conjunción o disyunción Dado un join de las forma se pueden aplicar una o más de las técnicas de join descritas anteriormente en cada condición individual, el resultado total consiste en las tuplas del resultado intermedio que satisfacen el resto de las condiciones. Estas condiciones se pueden ir comprobado según se generen las tuplas. La implementación de la disyunción es homóloga a la conjunción.
Outer Join (Join externos)
Un outer join es una extensión del operador join que se utiliza a menudo para trabajar con la información que falta.
Optimizacion de consultas distribuidas
Para poder optimizar una consulta necesitamos tener claras las propiedades del algebra relacional para asegurar la reformulacion de la consulta, al optimizar una consulta obtenemos los siguientes beneficios:
-minimizar costos
-Reducir espacios de comunicaciones
-Seguridad en envios de informacion
Optimización de consultas
El objetivo del procesamiento de consultas en un ambiente distribuido es transformar una consulta sobre una base de datos distribuida en una especificación de alto nivel a una estrategia de ejecución eficiente expresada en un lenguaje de bajo nivel sobre bases de datos locales.
Así, el problema de optimización de consultas es minimizar una funcion de costo tal que la funcion del costo total = costo de I/O + costo de CPU + costo de comunicació.
Los diferentes factores pueden tener pesos diferentes dependiendo del ambiente distribuido en el que se trabaje. Por ejemplo, en las redes de área amplia (WAN), normalmente el costo de comunicación domina dado que hay una velocidad de comunicación relativamente baja, los canales están saturados y el trabajo adicional requerido por los protocolos de comunicación es considerable. Así, los algoritmos diseñados para trabajar en una WAN, por lo general, ignoran los costos de CPU y de I/O. En redes de área local (LAN) el costo de comunicación no es tan dominante, así que se consideran los tres factores con pesos variables.
Optimización Global de Consultas
Dada una consulta algebraica sobre fragmentos, el objetivo de esta capa es hallar una estrategia de ejecución para la consulta cercana a la óptima. La estrategia de ejecución para una consulta distribuida puede ser descrita con los operadores del álgebra relacional y con primitivas de comunicación para transferir datos entre nodos. Para encontrar una buena transformación se consideran las características de los fragmentos, tales como, sus cardinalidades. Un aspecto importante de la optimización de consultas es el ordenamiento de juntas, dado que algunas permutaciones de juntas dentro de la consulta pueden conducir a un mejoramiento de varios órdenes de magnitud. La salida de la capa de optimización global es una consulta algebraica optimizada con operación de comunicación incluidas sobre los fragmentos.
Optimización Local de Consultas
El trabajo de la última capa se efectúa en todos los nodos con fragmentos involucrados en la consulta. Cada subconsulta que se ejecuta en un nodo, llamada consulta local, es optimizada usando el esquema local del nodo. Hasta este momento, se pueden eligen los algoritmos para realizar las operaciones relacionales.
jueves, 30 de abril de 2015
Actividad #15
Enlace para abrir la base de datos
https://drive.google.com/open?id=0BwdKiO11D1ZDWmZpN3BwN0p5Ylk&authuser=0
https://drive.google.com/open?id=0BwdKiO11D1ZDWmZpN3BwN0p5Ylk&authuser=0
jueves, 26 de marzo de 2015
Actividad #14
Que es la replicacion de una base de datos distribuida
Replicación es el proceso de copiar y administrar objetos de base de datos, tales como tablas, hacia múltiples bases de datos en localidades remotas que son parte de un sistema de bases de datos distribuido. Los cambios ejecutados en una localidad son capturados y guardados local mente antes de ser aplicados a las localidades remotas. Los términos sistemas de bases de datos distribuidas y replicación de bases de datos, están relacionados, pero no son equivalentes. En un sistema puro de bases de datos distribuidas se maneja o administra una sola copia de todos los objetos de la base de datos y sus datos, es decir que existe de manera única la ocurrencia de un objeto de base de datos en todas las localidades, es decir la información se encuentra particionada de manera horizontal entre todas las localidades. Las aplicaciones en una base de datos distribuida utilizan transacciones distribuidas para acceder y modificar tanto los datos
locales como remotos.
El término replicación se refiere a la operación de copiar y administrar objetos de base de datos en múltiples bases de datos a lo largo de un sistema distribuido, en este caso, existen varias copias del mismo objeto en diferentes localidades. Dado que la replicación depende de una tecnológica de base de datos distribuida, la replicación ofrece beneficios en las aplicaciones, que no son posibles en un ambiente puro de base
de datos distribuida, tal como la disponibilidad y rendimiento.
Hay 2 tipos de replicacion:
-Replicación básica: las réplicas de tablas se gestionan para accesos de sólo lectura. Para modificaciones, se deberá acceder a los datos del sitio primario.
-Replicación avanzada (simétrica): amplían las capacidades básicas de sólo- lectura de la replicación, permitiendo que las aplicaciones hagan actualizaciones a las réplicas de las tablas, a través de un sistema replicado de la base de datos. Con la replicación avanzada, los datos pueden proveer lectura y acceso a actualizaciones a los datos de las tablas.
Ventajas de replicacion
-Disponibilidad.-El modo en que la replicación incrementa la disponibilidad de los datos para los usuarios y aplicaciones.
-Fiabilidad.- Al haber múltiples copias de los datos disponibles en el sistema, se dispone de un mecanismo excelente de recuperación cuando existan fallos en nodos.
-Rendimiento.- Se mejora para las transacciones de consulta cuando se introduce la replicación en un sistema que estuviera aquejado de sobrecarga de recursos centralizados.
-Reducción de la carga.- Modo en que se utiliza la replicación para distribuir datos en ubicaciones remotas
-Copia de seguridad:En condiciones normales, una base de datos replicada de forma correcta es válida como copia de seguridad.Además se puede realizar copias de seguridad usando un servidor esclavo para así no interferir al servidor maestro.
-Mejorar la escalabilidad:Podríamos configurar nuestras aplicaciones para balancear las consultas de lectura (SELECT) entre los servidores replicados.
-Alta disponibilidad:En aplicaciones y entornos en donde sólo se requieren lecturas, podríamos configurar nuestras aplicaciones para balancear las consultas de lectura (SELECT) entre los servidores replicados de manera que si uno se cae se continue prestando servicio.
https://drive.google.com/file/d/0BwdKiO11D1ZDRFhlY1M0aGVvY28/view?usp=sharing
https://drive.google.com/file/d/0BwdKiO11D1ZDRFhlY1M0aGVvY28/view?usp=sharing
miércoles, 25 de marzo de 2015
Actividad #13
Base de datos distribuidas y arquitectura cliente servidor
• Sistema de computación distribuido: elementos de procesamiento que cooperan en la ejecución de tareas,interconectados por una red de ordenadores.• BD distribuida (BDD): son varias BD interrelacionadas lógicamente y situadas en diferentes nodos de una red de ordenadores.
• SGBD distribuido: el que gestiona BD distribuidas de forma transparente para el usuario (éste ve las BD como si fueran una sola BD centralizada)
• Ventajas de las BDD:
– Localización transparente de los datos:
– Transparencia en los nombres:
– Transparencia de fragmentación
Fragmentancion:
Fragmentar se refiere a decidir donde situar las partes de BDD
existen fragmentación vertical, fragmentación vertical derivada fragmentación mixta.
Replicacion y Asignación:
La replicación mejora la disponibilidad de los datos, caso extremo: tener una réplica de la BD completa en
cada sitio (ordenador):
– Ventajas: mejora el rendimiento local y global además de la disponibilidad (con un sitio activo se
accede a toda la BD)
– Inconvenientes: actualizaciones más costosas (se deben realizar en todas las réplicas para mantener la
coherencia). El control de concurrencia y recuperación es también más costoso.
• Asignación: dónde se sitúan los fragmentos y réplicas
– La elección del lugar y el grado de replicación depende de los objetivos de rendimiento y disponibilidad. También del tipo de transacciones y su frecuencia.
– Encontrar una solución óptima o incluso una buena es un problema complejo
Clientes Servidor (arquitectura nivel 2 )
La forma habitual de dividir la funcionalidad del SGBD entre cliente y servidor ha sido la arquitectura de 2 niveles:
– Servidor (o servidor SQL): donde se sitúa el SGBD. Una BDD se situaría en varios servidores.
– Clientes:
• Envían consultas/actualizaciones a servidores
• Tienen interfaces SQL, de usuario y funciones de interfaz del lenguaje de programación
• Consultan en el diccionario de datos la información sobre la distribución de la BD entre los servidores.
Tienen módulos que descomponen consultas globales en varias locales a cada servidor
• Interacción cliente-servidor (arquitectura de 2 niveles):
– El cliente analiza la consulta del usuario. La descompone en varias subconsultas y envía cada una a un servidor.
– Cada servidor ejecuta su subconsulta y devuelve el resultado al cliente
– El cliente combina los resultados recibidos y muestra al usuario el resultado de su consulta
martes, 10 de marzo de 2015
Actividad #11
¿Qué es una transacción?
-Una transacción es una unidad de la ejecución de un
programa que accede y posiblemente actualiza varios
elementos de datos.
¿Qué significa ACID? y defina cada una de las palabras que forman las siglas
-Atomicidad. O todas las operaciones de la transacción
se realizan adecuadamente en la base de
datos o ninguna de ellas.
• Consistencia. La ejecución aislada de la transacción
(es decir, sin otra transacción que se ejecute
concurrentemente) conserva la consistencia de la
base de datos.
• Aislamiento. Aunque se ejecuten varias transacciones
concurrentemente, el sistema garantiza que para cada par de transacciones Ti y Tj, se cumple
que para los efectos de Ti, o bien Tj ha terminado
su ejecución antes de que comience Ti , o bien que
Tj ha comenzado su ejecución después de que Ti
termine. De este modo, cada transacción ignora al
resto de las transacciones que se ejecuten concurrentemente
en el sistema.
• Durabilidad. Tras la finalización con éxito de una
transacción, los cambios realizados en la base de
datos permanecen, incluso si hay fallos en el sistema.
Tx significa Transmisión o Transmisor (en este caso Transacción).
¿Para que nos sirve el Rollback?
-Para Retroceder
Defina Integridad de datos
-El componente de mantenimiento de la integridad de una base de
datos asegura que las actualizaciones no violan las restricciones de integridad
que hayan especificado sobre los datos. El componente de seguridad de una
base de datos incluye la autenticación de usuarios y el control de acceso para
restringir las posibles acciones de cada usuario.
La concurrencia es la propiedad de los sistemas que permiten que múltiples procesossean ejecutados al mismo tiempo, y que potencialmente puedan interactuar entre sí.
Podría definirse como la coherencia entre todos los datos de la base de datos.
- Modelo de estructura de transacciones: Es importante considerar si las transacciones son planas o pueden estar anidadas.
- Consistencia de la base de datos interna: Los algoritmos de control de datos semántico tienen que satisfacer siempre las restricciones de integridad cuando una transacción pretende hacer un commit.
- Protocolos de confiabilidad: En transacciones distribuidas es necesario introducir medios de comunicación entre los diferentes nodos de una red para garantizar la atomicidad y durabilidad de las transacciones. Así también, se requieren protocolos para la recuperación local y para efectuar los compromisos (commit) globales.
- Algoritmos de control de concurrencia: Los algoritmos de control de concurrencia deben sincronizar la ejecución de transacciones concurrentes bajo el criterio de correctitud. La consistencia entre transacciones se garantiza mediante el aislamiento de las mismas.
- Protocolos de control de réplicas: El control de réplicas se refiere a cómo garantizar la consistencia mutua de datos replicados. Por ejemplo se puede seguir la estrategia read-one-write-all (ROWA).
- Activa (Active): El estado inicial; la transacción permanece en este estado durante su ejecución.
- Parcialmente comprometida (Uncommited): Después de ejecutarse la ultima transacción.
- Fallida (Failed): Tras descubrir que no se puede continuar la ejecución normal.
- Abortada (Rolled Back): Después de haber retrocedido la transacción y restablecido la base de datos a su estado anterior al comienzo de la transacción.
- Comprometida (Commited): Tras completarse con éxito.
lunes, 9 de marzo de 2015
Actividad #10
Tipos De Transparencia en BDD
-Transparencia sobre la localización de datos. el comando que se usa es
independiente de la ubicación de los datos en la red y del lugar en donde la
operación se lleve a cabo. Por ejemplo, en Unix existen dos comandos para hacer una copia de archivo. Cp se utiliza para copias locales y rcp se utiliza para copias remotas. En este caso no existe transparencia sobre la localización.
-La transparencia a nivel de fragmentación de datos. permite que cuando los objetos
de la bases de datos están fragmentados, el sistema tiene que manejar la conversión de
consultas de usuario definidas sobre relaciones globales a consultas definidas sobre
fragmentos. Así también, será necesario mezclar las respuestas a consultas fragmentadas
para obtener una sola respuesta a una consulta global. El acceso a una base de datos
distribuida debe hacerse en forma transparente.
La transparencia sobre replicación de datos. se refiere a que si existen réplicas de
objetos de la base de datos, su existencia debe ser controlada por el sistema no por el
usuario. Se debe tener en cuenta que cuando el usuario se encarga de manejar las
réplicas en un sistema, el trabajo de éste es mínimo por lo que se puede obtener una
eficiencia mayor. Sin embargo, el usuario puede olvidarse de mantener la consistencia de
las réplicas teniendo así datos diferentes.
Ejemplos De Fragmentacion en BDD
FRAGMENTACION HORIZONTAL


FRAGMENTACION VERTICAL

jueves, 12 de febrero de 2015
Actividad 4
Bases de datos centralizada
Concepto.-
Es una base de datos almacenada en su totalidad en un solo lugar físico, es decir, es una base de datos almacenada en una sola máquina y una sola CPU, en donde los usuarios trabajan en terminales que sólo muestran resultados.Son aquellos que se ejecutan en un único sistema informático sin interaccionar con ninguna otra computadora.
Bases de datos distribuida
Concepto.-
Es una colección de datos que pertenecen lógicamente a un sólo sistema, pero se encuentra físicamente esparcido en varios "sitios"de la red. Un sistema de base de datos distribuidos se compone de un conjunto de sitios, conectados entre sí mediante algún tipo de red de comunicaciones, en el cual:
• Cada sitio es un sistema de base de datos en sí mismo.
• Los sitios trabajan en conjunto si es necesario con el fin de que un usuario de cualquier sitio pueda obtener acceso a los datos de cualquier punto de la red tal como si todos los datos estuvieran almacenados en el sitio propio del usuario.
Cuadro comparativo entre base de datos centralizada y distribuida

Fuentes:
martes, 10 de febrero de 2015
Actividad 7
Arquitectura de las bases de datos distribuidas
La mayoría de los sistemas de manejo de bases de datos disponibles actualmente están basadas en la arquitectura ANSI-SPARC la cual divide a un sistema en tres niveles:interno, conceptual y externo

Aplicación de las bases de datos distribuidas
Los ambientes en los que se encuentra con mayor frecuencia el uso de bases de datos distribuidas son:
- Cualquier organización que tiene una estructura descentralizada. El enfoque distribuido de las bases de datos se adapta más naturalmente a la estructura de las organizaciones. Además, la necesidad de desarrollar una aplicación global (que incluya a toda la organización), se resuelve fácilmente con bases de datos distribuidas. Si una organización crece por medio de la creación de unidades o departamentos nuevos, entonces, el enfoque de bases de datos distribuidas permite un crecimiento suave. Además, como ya se ha mencionado en apartados anteriores, los datos se pueden colocar físicamente en el lugar donde se accede más frecuentemente, haciendo que los usuarios tengan control local de los datos con los que interactúan. Los casos más típicos son organismos gubernamentales y/o de servicio público.
- La industria de la manufactura, particularmente, aquella con plantas múltiples. Por ejemplo, la industria automotriz.
- Aplicaciones de control y comando militar.
- Líneas de transporte aéreo.
- Cadenas hoteleras.
- Servicios bancarios y financieros.
Ventajas de las bases de datos distribuidas
• Compartimiento de datos. Los usuarios de un nodo son capaces de acceder a los datos de otro nodo.
• Autonomía. Cada nodo tiene cierto grado de control sobre sus datos, en un sistema centralizado, hay un administrador del sistema responsable de los datos a nivel global. Cada administrador local puede tener un nivel de autonomía local diferente.
• Disponibilidad. Si en un sistema distribuido falla un nodo, los nodos restantes pueden seguir funcionando. Si se duplican los datos en varios nodos, la transacción que necesite un determinado dato puede encontrarlo en cualquiera de los diferentes nodos.
Desventajas de las bases de datos distribuidas
• Coste de desarrollo del software. La complejidad añadida que es necesaria para mantener la coordinación entre nodos hace que el desarrollo de software sea más costoso.
• Mayor probabilidad de errores. Como los nodos que constituyen el sistema funcionan en paralelo, es más difícil asegurar el funcionamiento correcto de los algoritmos, así como de los procedimientos de recuperación de fallos del sistema.
• Mayor sobrecarga de procesamiento. El intercambio de mensajes y ejecución de algoritmos para el mantenimiento de la coordinación entre nodos supone una sobrecarga que no se da en los sistemas centralizados.
Fuentes:
viernes, 6 de febrero de 2015
Actividad 6
Uso de la bases de datos distribuidas en el sector productivo
En los sectores en que son mas utilizadas las BDD son:
- Bancos
- Escuelas
- Ajencia de viajes
- Hopitales
- En los ejercitos Hoteles
- Empresas
- Precisamente en el sector productivo y gubernamental de los distintos países.
Para cualquier organización que está operando en el sector productivo de un país, es indispensable contar con medios para el control de la información, ya que de ello depende en gran medida que se lleguen a tomar decisiones en momentos de crisis económica o problemas legales.
El impacto de las bases de datos tanto en el sector privado como gubernamental, ha sido tan grande que prácticamente todas las empresas desde las PyMES hasta las multinacionales (de gobierno o privadas) hacen uso de las bases de datos.
Fuentes
Transparencia de datos
La transparencia se puede entender como la separación de la semántica de alto nivel de un sistema de las aspectos de bajo nivel relacionados a la implementación del mismo. Un nivel de transparencia adecuado permite ocultar los detalles de implementación a las capas de alto nivel de un sistema y a otros usuarios.
En sistemas de bases de datos distribuidos el propósito fundamental de la transparencia es proporcionar independencia de datos en el ambiente distribuido. Se pueden encontrar diferentes aspectos relacionados con la transparencia. Por ejemplo, puede existir transparencia en el manejo de la red de comunicación, transparencia en el manejo de copias repetidas o transparencia en la distribución o fragmentación de la información.
La independencia de datos es la inmunidad de las aplicaciones de usuario a los cambios en la definición y/u organización de los datos y viceversa. La independencia de datos se puede dar en dos aspectos: lógica y física.
- Independencia lógica de datos. Se refiere a la inmunidad de las aplicaciones de usuario a los cambios en la estructura lógica de la base de datos. Esto permite que un cambio en la definición de un esquema no debe afectar a las aplicaciones d eusuario. Por ejemplo, el agregar un nuevo atributo a una relación, la creación de una nueva relación, el reordenamiento lógico de algunos atributos.
- Independencia física de datos. Se refiere al ocultamiento de los detalles sobre las estructuras de almacenamiento a las aplicaciones de usuario. Esto es, la descripción física de datos puede cambiar sin afectar a las aplicaciones de usuario. Por ejemplo, los datos pueden ser movidos de un disco a otro, o la organización de los datos puede cambiar.
La transparencia al nivel de red se refiere a que los datos en un SBDD se accesan sobre una red de computadoras, sin embargo, las aplicaciones no deben notar su existencia. La transparencia al nivel de red conlleva a dos cosas:
- Transparencia sobre la localización de datos. Esto es, el comando que se usa es independiente de la ubicación de los datos en la red y del lugar en donde la operación se lleve a cabo. Por ejemplo, en Unix existen dos comandos para hacer una copia de archivo. Cp se utiliza para copias locales y rcp se utiliza para copias remotas. En este caso no existe transparencia sobre la localización.
- Transparencia sobre el esquema de nombramiento. Lo anterior se logra proporcionando un nombre único a cada objeto en el sistema distribuido. Así, no se debe mezclar la información de la localización con en el nombre de un objeto.
La transparencia sobre replicación de datos se refiere a que si existen réplicas de objetos de la base de datos, su existencia debe ser controlada por el sistema no por el usuario. Se debe tener en cuenta que al cuando el usuario se encarga de manejar las réplicas en un sistema, el trabajo de éste es mínimo por lo que se puede obtener una eficiencia mayor. Sin embargo, el usuario puede olvidarse de mantener la consistencia de las réplicas teniendo así datos diferentes.
La transparencia a nivel de fragmentación de datos permite que cuando los objetos de la bases de datos están fragmentados, el sistema tiene que manejar la conversión de consultas de usuario definidas sobre relaciones globales a consultas definidas sobre fragmentos. Así también, será necesario mezclar las respuestas a consultas fragmentadas para obtener una sola respuesta a una consulta global. El acceso a una base de datos distribuida debe hacerse en forma transparente.
En resumen, la transparencia tiene como punto central la independencia de datos. Los diferentes niveles de transparencia se puede organizar en capas . En el primer nivel se soporta la transparencia de red. En el segundo nivel se permite la transparencia de replicación de datos. En el tercer nivel se permite la transparencia de la fragmentación. Finalmente, en el último nivel se permite la transparencia de acceso (por medio de lenguaje de manipulación de datos).

En resumen, la transparencia tiene como punto central la independencia de datos. Los diferentes niveles de transparencia se puede organizar en capas . En el primer nivel se soporta la transparencia de red. En el segundo nivel se permite la transparencia de replicación de datos. En el tercer nivel se permite la transparencia de la fragmentación. Finalmente, en el último nivel se permite la transparencia de acceso (por medio de lenguaje de manipulación de datos).
Fuentes
Fragmentacion de datos
Existen tres tipos de fragmentacion la horizontal, la vertical y la mixta
1.-Fragmentación Horizontal
- Una tabla T se divide en subconjuntos, T1, T2, ...Tn. Los fragmentos se definen a través de una operación de selección y su reconstrucción se realizará con una operación de unión de los fragmentos componentes.
- Cada fragmento se sitúa en un nodo.
- Pueden existir fragmentos no disjuntos: combinación de fragmentación y replicación.
Ejemplo:


2.-Fragmentación Vertical
- Una tabla T se divide en subconjuntos, T1, T2, ...Tn. Los fragmentos se definen a través de una operación de proyección.
- Cada fragmento debe incluir la clave primaria de la tabla. Su reconstrucción se realizará con una operación de join de los fragmentos componentes, pueden existir fragmentos no disjuntos: combinación de fragmentación y replicación.
Ejemplo:

3.-Fragmentación Mixta
- Como el mismo nombre indica es una combinación de las dos anteriores vistas he aquí un ejemplo a partir de una tabla fragmentada horizontalmente.
Ejemplo:

Fuentes
Suscribirse a:
Comentarios (Atom)